Where to start?
Short presentation on Processing Model from TEI Conference 2015 in Lyon
A showcase app running on eXist-db and GitHub repo for it.
Authors and Contributors
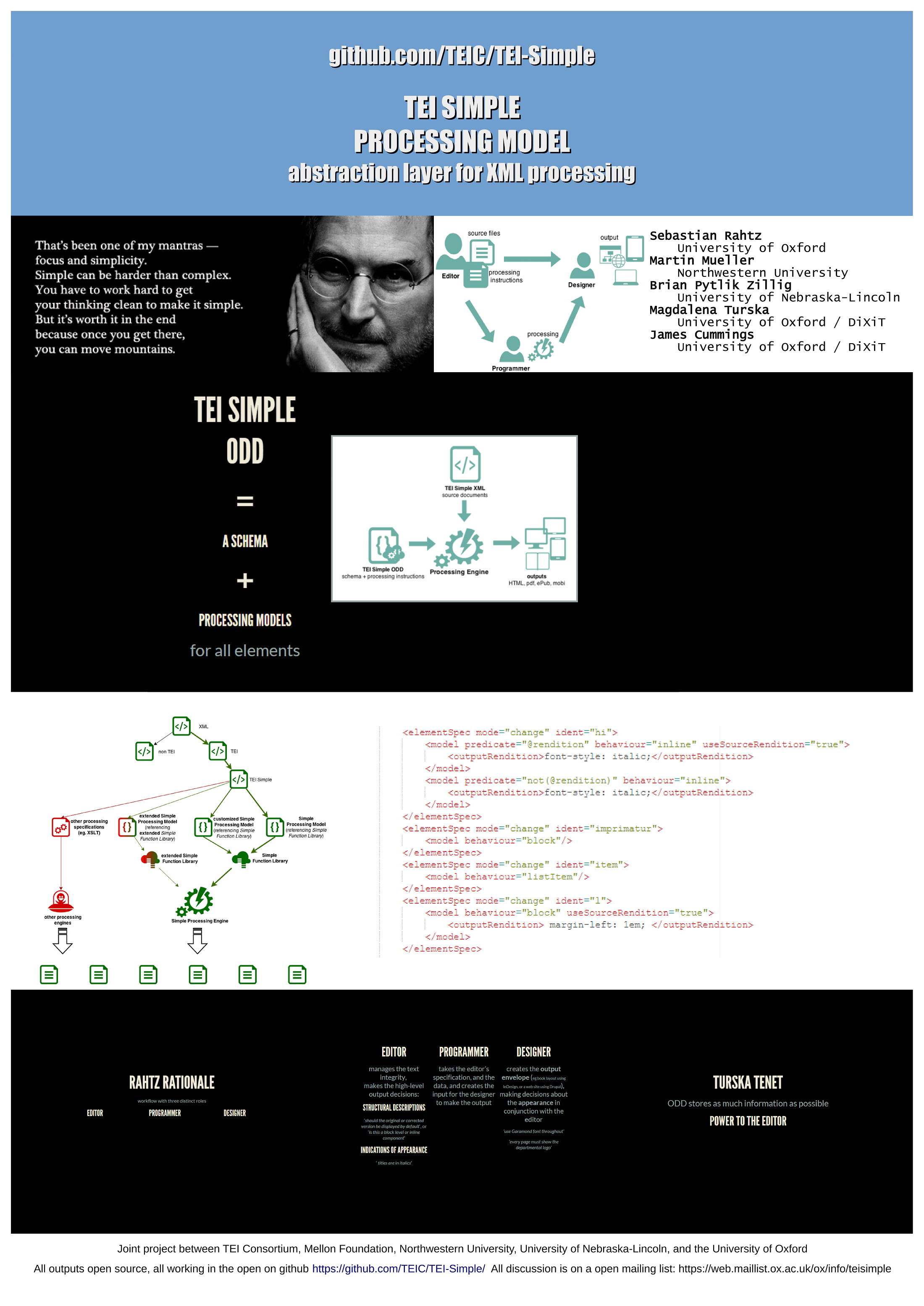
Background
The Text Encoding Initiative (TEI) has developed over 20 years into a key technology in text-centric humanities disciplines, with an extremely wide range of applications, from diplomatic editions to dictionaries, from prosopography to speech transcription and linguistic analysis. It has been able to achieve its range of use by adopting a descriptive rather than prescriptive approach , by recommending customization to suit particular projects, and by eschewing any attempt to dictate how the digital texts should be rendered or exchanged. However, this flexibility has come at the cost of relatively limited success in interoperability. In our view there is a distinct set of uses (primarily in the area of digitized ‘European’-style books) that would benefit from a prescriptive recipe for digital text; this will sit alongside other domain-specific, constrained TEI customizations, such as the very successful Epidoc in the epigraphic community. TEI Simple may become a prototype for a new family of constrained customizations. For instance, a TEI Simple MS for manuscript based work could be built on top of the ENRICH project, drawing on many of the lessons and some of the code for TEI Simple.
The TEI has long maintained an introductory subset (TEI Lite) and a constrained customization for use in outsourcing production to commercial vendors (TEI Tite), but the former permits enormous variation and the latter neglects anything requiring expertise in the source material. More importantly, neither addresses processing of the encoded text. The present project can be viewed in some ways as a revision of TEI Lite, re-examining the basis of the choices therein, focusing it for a more specific area, and adding a "cradle to grave" processing model that associates the TEI Simple schema with explicit and standardized options for displaying and querying texts. This means being able to specify what a programmer should do with particular TEI elements when they are encountered, allowing programmers to build stylesheets that work for everybody and to query a corpus of documents reliably.
This proposal, TEI Simple, will focus on interoperability, machine generation, and low-cost integration. The TEI architecture facilitates customizations of many kinds; TEI Simple aims to produce a complete 'out of the box' customization which meets the needs of the many users for whom the task of creating a customization is daunting or seems irrelevant. TEI Simple in no way intends to constrain the expressive liberty of encoders who do not think that it is either possible or desirable to follow this path. It does, however, promise to make life easier for those who think there is some virtue in travelling that path as far as it will take you, which for quite a few projects will be far enough. Some users will never feel the need to move beyond it, others will outgrow it, and when they do they will have learned enough to do so.
‘Comparability and interoperability with other resources’ are an increasingly important topic on various Digital Humanities agendas. Echoes of it are found in a recent ‘work set construction’ Mellon grant to the Hathi Trust Research Centre. Under the heading ‘Wissenschaftliche Sammlungen’ it is a major part of an ambitious DARIAH project anchored at the SUB Göttingen. Progress towards it may be slow, tedious, and partial, but ‘simplicity, interoperability, broad use and reuse’, and ‘comparability and interoperability with other resources’ are important goals to keep in mind for many purposes. For a lot of current and future users of the TEI the really important benefits come from the simple stuff, and beyond some level of complexity they begin to feel some sympathy with Andrew Prescott's not very kind phrase about ‘angels dancing on angle brackets.’ [http://ahh.sagepub.com/content/early/2011/11/30/1474022211428215]
A major driver for this project is the texts created by phase 1 of the EEBO-TCP project, which will be placed in the public domain on 1 January 2015. Another 45,000 texts will join over the following five years, creating by 2020 an archive of 70,000 consistently encoded books published in England from 1475 to 1700, including works of literature, philosophy, politics, religion, geography, science and all other areas of human endeavor. When we compare the query potential of the EEBO TCP texts in their current and quite simple encoding with flat file versions of those text, it is clear that the difference in query potential is very high, especially if you add to that coarse encoding simple forms of linguistic annotation or named entity tagging that can be added in a largely algorithmic fashion. During 2012 and 2013 extensive work has been undertaken at Northwestern, Michigan and Oxford to enrich these texts and bring them into line with the current TEI Guidelines (where necessary working with the TEI to modify the Guidelines). TEI Simple will use this corpus as a point of departure and will provide its users with a friendlier environment for manipulating EEBO texts in various projects. But TEI Simple should not be understood as an EEBO specific project. We believe that, given the extraordinary degree of internal diversity in the EEBO source files, a project that starts from them can, with appropriate modifications, accommodate a wide range of printed texts differing in language, genre, or time and place of origin.
Objectives
TEI Simple has the following high-level objectives:
The aim is to lower the access barriers to working with TEI-encoded texts in various web environments. Programmers familiar with a particular web environment, whether Django, Drupal, eXist, Ruby on Rails, or others will be able to integrate TEI Simple-based projects into their environment with moderate effort and with no more than their usual tools and skills.
The project will adhere to the following principles:
- As little overlap as possible, and as much compatibility as possible, with existing repository projects
- At least as prescriptive as level 3 of the Best Practices for TEI in Libraries
- Encompassing I18N principles at all times
- Useable implementations of all features
Outcomes from TEI Simple, consisting of a documented definition in ODD of the TEI subset, a set of processing rules, and extensions to the TEI ODD language to record processing expectations, will be fully integrated into the TEI infrastructure with ongoing maintenance by the TEI Technical Council.
TEI Simple is intended to be complementary to community projects like the TAPAS project, and to the established work of TextGrid, the German Text Archive (the DTA ‘base format’, which shares many of the goals of TEI Simple) and other national projects.